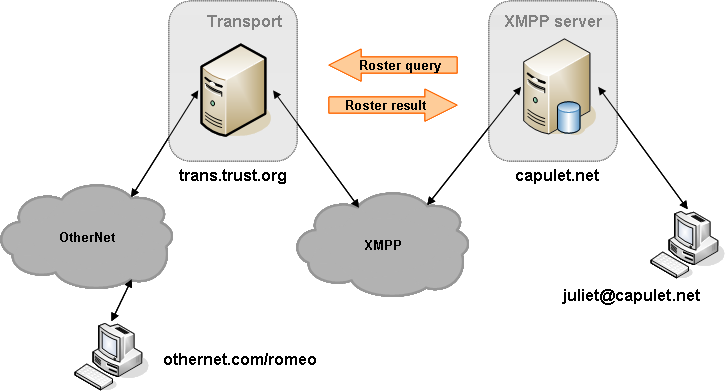
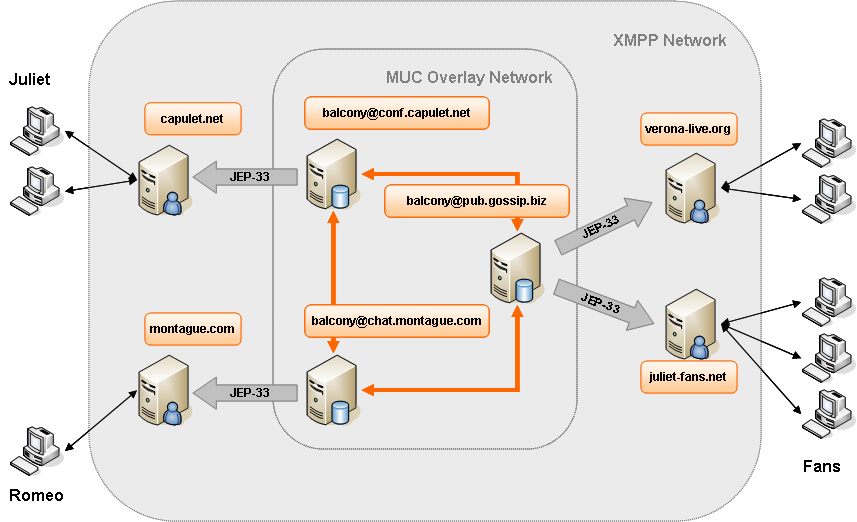
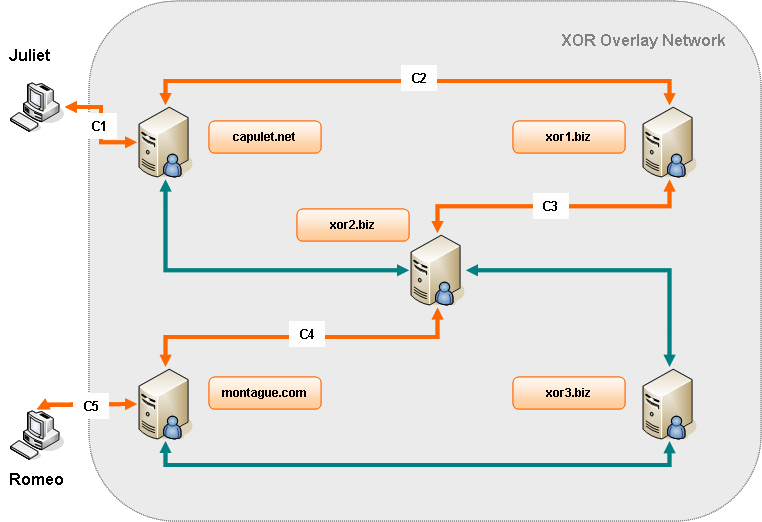
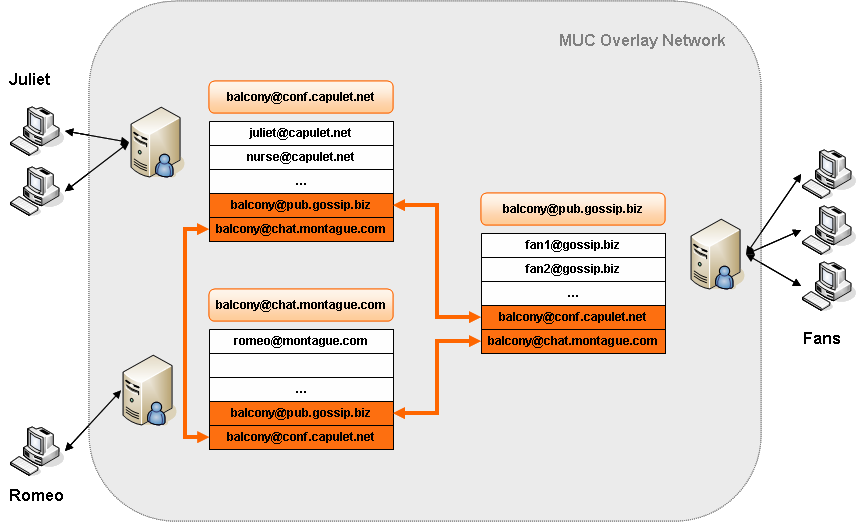
Left to the implementation
Having looked various experiments in the field of digital identity, I recently decide to use an interesting contact filtering feature offered by certain i-brokers. This service allows you to filter out only dully identified communications addressed to you from a web page link. As I was not interested in joining any particular community, I decided to create an i-name on a generic i-broker. The registration process went almost well until after giving my payment details the system spat and “application error (Rail)” page after briefly showing a receipt page with a transaction number… So much for my financial records.
Not stopping at this little detail, I logged into the i-broker using my newly acquired i-name, in order to setup the contact service. At this point the system warned me that the i-broker “is not quite ready” and as a consequence they “plan to have the new Contact Service up and running very shortly”. As a matter of fact I would have appreciated being given this information as a note on the registration page. This notice may have resulted in me deciding to postpone the registration process.
That made two disappointments in a row. The i-broker service had been through a beta period not long ago. So, I thought it worth sharing my experience with the i-broker team. I happily clicked on the “contact us” link, which brought me to a “this page does not exist” warning… Interesting navigation. At that point I went back to the previous i-broker beta site where the contact page was available. Obviously, the form to contact the technical team was using the “contact filtering” service whic was available in beta. The form provided an option to use my newly registered i-name. I duly reported my ordeal and submitted the form. At this moment the system replied telling me the i-name I just registered and logged in with was unknown … I was under the impression i-names’ major advantage was in using XRI to be resolvable everywhere.
Beyond the early disappointment created by this experience, I believe there are a few lessons to be learned. When deploying a public facing application, I believe it is paramount to provide a customer:
- An easy an enjoyable user experience,
- A clear indication of the features available at this moment,
- A robust application framework rather than the latest hyped tools,
- A working demonstration of the services provided.
Failing to demonstrate these simple ingredients of any web application is in my opinion one of the major cause of service disappearance and bad reputation. I often read in standards or specifications that “it is all left to the implementation”. This is excatly the point, and the responsability of the implementers. I personally would not like to see i-brokers disappear so soon.
Technorati Tags: Identity, Digital privacy, Digital reputation, Digital identity, AntecipateLabels: XMPP
posted by Jean-Louis Seguineau at 11:24 pm
![]()